I’ll be posting more frequently on Substack until I inevitably self-host again at some point in the future. Check out my first post here!
Thesis Musings 2: Potential Pivot and Clarification
Reflection
This week I had some thoughts that might lead me down a path to a clearer thesis topic. I was interviewed by a group of Penn Integrated Product Design grad students about my Biodesign Competition project. At one point, they asked me if I considered myself a biodesigner, and I hesitated, and ultimately said no. Why? I’ll come back to that later.
I studied decision processes and public policy in undergrad. When I graduated in 2010, there were very few jobs called “UX Designer.” In fact, my concentration, Decision Processes, could have easily been renamed “Behavioral Economics,” but that field was also still in its infancy in popular understanding. Yet even as students, we could see how the emerging theories we studied were already shaping software design and policy. “Nudges” were being implemented to set default behaviors when signing up for, say, savings accounts -- something informed by behavioral research. Particular colors were being used to incentivize or disincentive actions. It was increasingly clear that what we were studying was being implemented in practice, both in software and within public policy, and that the field of design was expanding beyond fashion, furniture, hardware, and graphics to include more interdisciplinary philosophies and applications.
Now in 2020, we’ve seen both the bright and dark sides of the influence of behavioral research on product design and policy, and we have an entire industry built around incorporating our academic understanding of behavior into the process of design. “UX Design” is a common job title that has subfields (i.e. “UX research”) and is even a field of study itself now. If I were a Decision Processes student today, I would have a set of obvious jobs to consider upon graduating.
We’re currently at a similar inflection point, I believe, in the field of “biodesign.” There is an emerging set of beliefs, tools, and practices that are loosely tied together with the term “biodesign,” but with a very fluid definition of what it might mean, and few job opportunities explicitly penned.
A Fast Company article from 2017 says that biodesign is “a growing movement (literally) of scientists, artists, and designers that integrates organic processes and materials into the creation of our buildings, our products, and even our clothing.” In perhaps the definitive text on the current state of Biodesign, William Myers says that “unlike biomimicry or the popular but vague "green design," biodesign refers to the incorporation of living organisms as essential components in design, enhancing the function of the finished work.” These definitions leave a lot of room for further clarification, and might beg more questions than they answer.
One question that follows immediately: are there “biodesigner” jobs? What does LinkedIn look like when searching “biodesigner?” How does that compare with “UX designer?”


In the “Biodesign” search, there are only a few results with “biodesigner” in the job title, and few companies that are oriented around “biodesign.” UX, on the other hand, has an entirely different page layout given how popular both the title and the field is.
In addition to how biodesign might look on LinkedIn, another few questions might be:
“What philosophies or frameworks might guide a biodesign practice?”
“What is the equivalent of “Human Centered Design” for biodesign… or are they actually compatible, and biodesign is a discipline, in a different part of the design ecosystem from a framework like HCD?”
“What would distinguish biodesign from, say, industrial design?”
All of these circle around the bigger question of defining what biodesign is today, where it might go in the future, both pragmatically in the form of jobs, companies, and labels, but also in the form of philosophies that shape how we approach thinking about designing the world around us and around the other life forms we live with.
When I was asked whether I was a biodesigner, I said “no” because I felt the word was too vague; that it could be too easily misconstrued, or misunderstood. I said I might be more comfortable with bio-artist; perhaps because “artist” itself is such a broad, open-ended label at this point, that it could subsume the prefix “bio” without batting an eyelid…
As I reflected about my thought processes and my design processes, however, I noticed that I did have a pattern that might not fit under an “established” design school of thought. I begin my design process with a process of decomposition; of breaking the whole of an entity (a problem, a feeling, a material…) into its constituent parts. I often think about how those parts can be transformed, recombined, recycled into new wholes. I realized that my thought process is informed both by the computer science-y idea of “decomposition” and the biological idea of “decomposition” -- and that with some further thought, I may be able to articulate a philosophy and set of tools for using this sort of decompositional framework for designing -- ideating, prototyping, problem solving.
So, in a nutshell, I may focus my thesis on elaborating on the definition(s) of biodesign, of placing it within the world of existing design school of thought, and then establishing a sub-framework of biodesign of my own, which right now would loosely be described at “Decomposition Design.”
What might this look like:
Research “paper”
Does not need to be entirely written -- could include multimedia, especially video and animation
Does not need to be a linear experience for the “reader”
There are many questions to answer, and many paths that might follow from the broader question of defining biodesign
Should include interviews with people across the biodesign world, broader design world, and lay people who might not currently know what biodesign is/might become
A series of experiments
objects as examples of the schools of thought within biodesign
Especially important to do this if I decide to develop/articulate my own design paradigm
Schools of thought
Resilience design
Multi-species-centered design
Biomimicry
Decomposition design (my framework)
Digital Currencies, Blockchain, Future of Finance Reaction 2
From October 2020// reaction essay for NYU Stern/Law School Digital Currency, Blockchain, Future of Finance course with Drew Hinkes and David Yermack
Bitcoin has come under fire for a whole host of issues: its energy consumption, the political ideology of many enthusiasts, its volatility, the shady transactions that fueled early usage, the potentially unwarranted hype, and so on. We’ve picked apart a number of these critiques in class through a much more nuanced prism. One critique that I think has more validity than many of the others is that the Bitcoin proof-of-work task, finding a random number, is pointless-yet-effective. The question raised in class and by other blockchain thinkers is whether we can devise a proof-of-work task that is cryptographically and algorithmically sound while also useful in the broader world. I have one idea I would like to explore -- protein folding as proof-of-work. I’ll start with a brief summary of proof-of-work as a verification tool, review the basics of protein folding and why it is important, then analyze whether protein folding could be a useful proof-of-work task for a blockchain. Finally, I’ll highlight some folks who seem to be thinking along the same lines already.
Let’s start with a quick summary of the mechanics of proof-of-work verification. Every blockchain is, at its simplest, a series of transactions that account for the exchanges of coins between parties. Those transactions need to be verified so that the current state of ownership of coins is accurate; this process of verification-in-chunks is what ultimately creates “blocks” that are “chained” together to form a blockchain. The process of verification itself can take different forms, but the one I’m interested in in this paper, proof-of-work (POW), works as follows:
All transactions since the previous verification event are grouped together into a block.
The blockchain in question poses a challenge to all prospective verifiers-- miners-- that is challenging to complete, but easy to verify.
Miners compete to see who can complete the challenge as quickly as possible.
Miners who believe they are correct will broadcast their answer for others to check.
After enough miners (also called “nodes”) agree that the answer is correct, the winning miner will receive a reward.
The criteria that is most intriguing to me when thinking of alternative POW designs is that the verification challenge must be difficult to solve but easy to verify. In the Bitcoin blockchain protocol, this involves finding a random number, which when combined with all previous block encryptions, will produce another very-difficult-to-guess specific encryption value, or target. The challenge issuer -- in this case, an algorithm -- can simply announce a target for this round, allow miners to attempt to find a hash value that is lower than the target, and then, after someone has announced that they won, wait for other miners to combine the announced value with the other components of the encryption formula, and verify that it produces the right target value.
Abstracted a level up, in designing a new proof-of-work, we need to issue a challenge that has a solution, likely a single number or small combination of solutions, which can be plugged in to an algorithm to produce a very-unlikely-to-fake value. This lends itself to challenges that have discrete answers with measurable qualities of “correctness.” that could be used to plug in to this pseudo-algorithm:
Encrypt [POW solution + (previous blockchain info)] = Target value
If we asked people to find one way to arrive at the number 112 using multiplication of more than 2 numbers, we would be able to verify answers -- of which there are many -- and could use timestamps of answer submissions to determine who was correct first. If we issued a challenge that asked people to submit a paragraph about the nature of truth, we would not be able to evaluate the correctness of the output, and would not be able to complete the hashing function. In all of these configurations, we can also ask whether the challenge itself is worthwhile: what is the value of asking people to use their time and computational effort to find random numbers? Is there a better use for this effort than can still maintain a sound cryptographic and incentive design?
Let’s hold the algorithm design thoughts for a moment and switch gears to protein folding. What is it/why is it important?
Proteins, one of the most important building blocks of life, are composed of a chain of many amino acids. There are 20 unique amino acids found in our bodies, and each one has special characteristics that affect how they interact with each other, and with other molecules. Proteins can be visualized on paper as a chain of linked amino acids, but in 3D space, the electrical charges associated with different amino acids cause the chain to attract and repel itself, leading to a “folding” that gives proteins their unique shapes. The shapes of proteins expose some of those positive or negative charges to passing molecules, which may attract or repel those molecules. This property allows proteins to function in the myriad ways that they do; as enzymes, as membranes, as tissues, and many other important components of life and living systems.
Amino acid chains that make up individual protein molecules can be very large in humans; small ones are chains of 100 amino acids, normal ones can be 1000+. These chains can be a combination of essentially any of the 20 amino acids, leading to large combinatorial sets even for the smaller proteins. Any one of these combinations can take on different shapes when folded. Knowing all of the possible shapes of proteins is important in advancing our understanding of biological systems, but getting to a comprehensive understanding is currently extremely computationally intensive.
The stability of a shape, and the performance qualities of a protein can be measured along a number of dimensions. For the sake of space in this paper, I am going to link to an example from a protein folding competition website, where you can see how the challenge is designed. Suffice to say that there is a leaderboard with scores, and a number of factors that roll up in to that final score. Any of these components, from the final score to a lower level performance factor, could be used as the input that leads to a target value.
The structure for a competition that is difficult to complete but easy to verify already exists, as exhibited by fold-it. Foldit encourages manual folding and is used as an educational tool, but there are also computational versions of Foldit. In fact, there seems to be a project called FoldingCoin out of Stanford that attempts to tokenify protein folding, although judging by the current coin price (way less than 1c per coin), it does not seem to have taken off. The promise, however, is real: if we use our manual or computational firepower towards identifying the shape of more and more proteins, we will be able to produce a more robust understanding of the structure of life, and with that knowledge, better medicine and health, better biomaterials for manufacturing (a potential solution to some of our climate change issues), better food production, and more.
I’ve run out of space for this exercise (I know you all have a lot of these to read!) -- but this seems to be a potential topic/project for the final paper, specifically:
What are the mechanics for a protein folding-based blockchain, in much more detail
What efforts have already launched and why have they not succeeded
What are the potential security vulnerabilities and performance issues in this POW setup
If successful, what value could this sort of blockchain add to the world
Digital Currencies, Blockchain, Future of Finance Reaction 1
From September 2020// reaction essay for NYU Stern/Law School Digital Currency, Blockchain, Future of Finance course with Drew Hinkes and David Yermack
Week 1 Reaction
The course so far has been full of interesting ideas. I’ve referenced the very first lecture’s examination of the various ways to incentivize/disincentive behavior — through laws, architecture, markets, and norms — in multiple conversations with classmates and friends. The considerations of systems design when thinking about blockchains and regulatory regimes have clear parallels to the ways I might go about thinking about systems design at a smaller scale when working as a product manager and UX designer focusing on a software ecosystem.
However the topic that I’ve found most thought-provoking, related to both regulation and systems design but distinctly in its own category, is the role of trust in networks. Given that the Bitcoin architecture’s semantics are relatively new to me, I’ll spend the majority of this paper summarizing and illustrating my understanding of trust and Bitcoin’s approach to trustless design, and finish with some thoughts about the implications of this design. I will elaborate on the implications down the line, as I develop a more sophisticated understanding about how the technical architecture could lead to unsuspected behaviors.
A simple exploration of trust
I’ll start by trying to define trust. Trust, I think, requires one actor to become dependent on the actions of another actor, without certainty about whether that 2nd actor’s actions will be consistent with promises or expectations of the nature of their actions. For example, if I pay my apartment’s rent on September 30th in full before charging my roommate for his half, I trust that he will pay me back in a timely manner. Why might I trust him?
Perhaps it’s because he has a track record of paying debts in a timely manner. It could be that his failure to pay back would cause him sufficient tension and risk of harm -- we live in the same space -- that I assume he would not act against his interest. Perhaps he will give me collateral to insure against his non-payment. In all of these cases, I would need to compute the risk of failure to pay and decide whether it was sufficiently small for me to pay the rent in-full.
In this setup, I know my roommate quite well, and the transaction is just between our 2 parties. If he defaults, the trust between us will be broken, and I’ll assume the costs associated with that. What if, instead, I am looking to sublet my apartment to a stranger. How could I ensure that this stranger was able to pay? In order to build trust, perhaps that stranger would be willing to pre-pay the rent. But why would they trust that I wouldn’t run off with the money? Instead we might seek a trusted third party to accept the stranger’s rent payment and pay me upon successful delivery of the apartment.
Why would we trust this third party? Likely for the same reasons that I might trust my roommate -- history of trustworthiness, sufficient risk of harm to themselves upon failure, insurance. A motivated bad actor could exploit any of these; this is at the heart of Satoshi’s whitepaper.
Bitcoin’s approach to trustless network design
The Bitcoin whitepaper clearly identified trusted third parties in financial transactions as an unacceptable risk that could be removed by a system of trustless verification of transactions. Satoshi’s proposal has three key features:
A distributed ledger of timestamped transaction blocks, viewable to anyone
Cryptographic design that links all previous transactions with most recent transactions, leading to an effectively immutable ledger
A system of self-adjusting competitive incentives for verifying transactions that make coordination of false verifications extremely unlikely
Taken together, this system is designed to shift the responsibility of verifying transactions from a trusted third party to the crowd. Its assumption is that the incentives laid out in the system will attract a sufficient number of nodes to do the work of mining coins and verifying transactions to have the scale needed to mitigate the risks of manipulation.
Implications of trustless design
The first question to examine is whether this system is truly “trustless.” It is true that this design no longer requires a single trusted third party. Now, instead, trust is placed in the design itself; that there are sufficient checks to any attempts at sabotage. What are those different types of “attack” that the system designs against?
Satoshi notes in his introduction that “The system is secure as long as honest nodes collectively control more CPU power than any cooperating group of attacker nodes.” If attacker nodes controlled more CPU power than honest nodes, they would be able to coordinate a falsified transaction log of recent transactions, with exponential difficulty in replacing older transactions due to the Merkle Tree hashing structure. The potential for bad actors to accrue this level of power is probably empirically model-able, but in the absence of having done this exercise or researching existing work on the viability of this sort of attack, suffice to say that it would require huge levels of resources and coordination at this point in time to pull this off, and would probably only be able to be done by a “superpower” sovereign nation-state.
With this power, Satoshi argues that “If a greedy attacker is able to assemble more CPU power than all the honest nodes, he would have to choose between using it to defraud people by stealing back his payments, or using it to generate new coins. He ought to find it more profitable to play by the rules, such rules that favour him with more new coins than everyone else combined, than to undermine the system and the validity of his own wealth.”
Satoshi’s reasoning makes sense in the case of an infinite game -- that the interest is in continuing to accrue coins indefinitely.
If the game is deterministic -- that the entity with the most coins at a particular moment in time “wins” -- I believe the incentive to pull off a coordinated attack gets much higher. Using BTC’s blockchain mechanism for voting seems like a case where this type of deterministic system might manifest itself.
During our last class, I asked Scott Stornetta about blockchain voting schemes, and he mentioned that there are a number of compelling use cases already in-flight. I will be researching the existing work done on blockchain voting design to see how folks work around incentives to manipulate the blockchain under deterministic circumstances.
Thesis Musings
I’m at the beginning of my dive into thesis research. We officially began our thesis class at ITP 2 weeks ago, and were asked to write a little bit about what was on our mind.
Prompt: Write a short blog post on the big concept or passion or interest or questions you want to tackle (not the technology).
Yogurt is a food. Yogurt is alive. Yogurt was an accident. Yogurt is intentional. Yogurt is recursive. Yogurt is an archive.
A spoonful of yogurt might sound like nothing more than an occasional breakfast snack; but what if I told you that within that yogurt, we can find questions and answers touching on everything from experience design to metaphysics; systems architecture to the future of computing?
Yogurt has been in the human diet in various parts of the world for thousands of years. We know it as a tangy, smooth-textured dairy product that is in a distinct class from cheese, milk, kefir, butter, and the rest. We know how it’s made now, too — heat milk, let it cool, add a bit of previous yogurt, give it time, and voila– you’ve got yogurt. But it wasn’t always this simple.
Yogurt likely began as an accident. It probably went something like this: milk was left outdoors in a hot environment near some plants, where lactobacillus — a lactic acid producing bacteria — was crawling around. That bacteria found its way into the milk and metabolized the lactose in the milk to produce lactic acid. That lactic acid lowered the pH of the milk. The hot environment “cooked” the milk, changing the shape (denaturing) many of the proteins in the milk. The more acidic environment and the denatured proteins encouraged a re-formation of protein networks in the milk. Those new networks of proteins created a firmer texture, and the lower pH gave the milk its tangy taste. Some brave soul took a bite of that substance, liked it, maybe even felt good rather than sick, and perhaps tried to recreate it. Over many centuries and experiments, we now have a relatively reliable way of making yogurt.
The mechanics of the inner workings of yogurt, which I can go to in much more detail, are ripe for analogy to the ways that human systems form, de-form, transform, and re-form. Bookmark “resilience in networks,” and “transformation” as topics of interest, and yogurt as a lens through which to look at these topics.
Also bookmark “experience design” as a practice of interest, and the cultivation of spoiled milk into a repeatably delicious product as something that we can analyze as an act of intentional design, and extend into other food and non-food design processes.
As I mentioned above, yogurts are created from previous yogurts. They don’t have to be done this way, but in common practice, they are. In that sense, yogurts are recursive. A piece of the whole begets the next whole; the “next” is dependent on the “previous.” In Indian households it is very common to make yogurt at home, and yogurt starters are often an important item to bring along when moving from one place to another, or to share with family and friends when they come to a new place. We can trace lineage through yogurt — where did it come from, where did it branch, how did it transform? We can tell stories of migration, of immigration, through yogurt; both through people and through bacteria.
There are a few ways we could go about tracing the lineage of yogurt. One of those ways would take advantage of recent dramatic improvements in our collective ability to understand the biological makeup of the world around us. Genome sequencing has become orders of magnitude cheaper, with handheld DNA sequencing tools now available to hobbyists, with room for further improvements in hardware and cost well within reach. The study of genomics coupled with the techniques of bioinformatics, among other related fields, are giving us new information about both the “hardware” and “software” of life, and allowing us to identify specific species of invisible microorganisms in our environment. We even have the ability to “program” some genes. We’ve figured out ways to store information in DNA, and we’re beginning to understand the possibilities of using DNA instead of bits as the basis for computing. Taken together, we are starting to learn techniques that may give us new infrastructure-level tools to reimagine the ways in which we build the materials around us — both physical and digital. The uses of these technologies will not be neutral; we have to imagine and execute the uses of the technologies that we want to see exist.
It’s possible that yogurt already is a kind of archive in itself; I would like to explore whether we can use the bacterial makeup of yogurt as a way of identifying its ancestors in ways that are roughly similar to how we are able to identify our relatives using DNA. I’d also like to explore using DNA storage to embed oral histories of the Indian community in New York — my mom’s family was part of the early batch of Indian immigrants to arrive in Queens in the 70s — in the DNA of lactobacillus, and use that lactobacillus to make yogurt. I’d then want to demonstrate the ability to read out those files from the yogurt DNA.
Zooming out — I am trying to weave together a variety of interests and questions through an exploration of yogurt. It is possible that I’ll narrow in on one specific area: resilience in networks, transformation, lineage, stories of the Indian-American community’s roots, the future of biology and computing, infrastructure technology versus end uses, Vedic philosophy. It’s also possible that all of these can be refracted through one prism. Let the journey begin…
Traceroute
See here for the Traceroute assignment
The concept of a traceroute was entirely new to me prior to this course. I suppose I knew that when I searched for “espn.com” in my browser that my request would be routed through a number of intermediaries. I didn’t, however, spend much time thinking about the physical and digital entities along those hops, nor did I know that we had the power in our terminals to begin analyzing the physical geography of our own internet behavior via the traceroute command.
I chose to see what a path to “espn.com” looks like from my home device and from NYU. I’ve been going to espn.com since I think the website started; I was a religious Sportscenter viewer as a child, and still have a daily habit of checking the sports headlines. If only I had captured a traceroute from 1995-era espn.com up until now -- it would have been even more fascinating to see how things have changed!
NYU -> ESPN
My search from NYU to ESPN had 22 hops, with 6 of the stops returning a ***. The first 13 stops had NYU or .edu domains.
1 10.18.0.2 (10.18.0.2) 2.993 ms 2.020 ms 2.111 ms 2 coregwd-te7-8-vl901-wlangwc-7e12.net.nyu.edu (10.254.8.44) 23.613 ms 11.542 ms 4.040 ms 3 nyugwa-vl902.net.nyu.edu (128.122.1.36) 2.477 ms 2.274 ms 2.618 ms 4 ngfw-palo-vl1500.net.nyu.edu (192.168.184.228) 3.235 ms 2.935 ms 2.744 ms 5 nyugwa-outside-ngfw-vl3080.net.nyu.edu (128.122.254.114) 17.543 ms 2.714 ms 2.862 ms 6 nyunata-vl1000.net.nyu.edu (192.168.184.221) 3.050 ms 3.094 ms 2.833 ms 7 nyugwa-vl1001.net.nyu.edu (192.76.177.202) 3.047 ms 3.383 ms 2.922 ms 8 dmzgwa-ptp-nyugwa-vl3081.net.nyu.edu (128.122.254.109) 3.584 ms 3.769 ms 3.484 ms 9 extgwa-te0-0-0.net.nyu.edu (128.122.254.64) 3.545 ms 3.299 ms 3.292 ms 10 nyc-9208-nyu.nysernet.net (199.109.5.5) 4.031 ms 4.078 ms 3.842 ms 11 i2-newy-nyc-9208.nysernet.net (199.109.5.2) 4.124 ms 3.686 ms 3.505 ms 12 ae-3.4079.rtsw.wash.net.internet2.edu (162.252.70.138) 8.970 ms 9.097 ms 9.792 ms 13 ae-0.4079.rtsw2.ashb.net.internet2.edu (162.252.70.137) 9.741 ms 9.272 ms 9.777 ms
Once leaving the NYU space, the first IP address in Virginia is associated with Amazon.com -- presumably one of the AWS servers.
14 99.82.179.34 (99.82.179.34) 13.231 ms 10.645 ms 9.469 ms 15 * * *
The next 3 are also associated with Amazon, this time in Seattle:
16 52.93.40.229 (52.93.40.229) 10.573 ms
52.93.40.233 (52.93.40.233) 9.719 ms
52.93.40.229 (52.93.40.229) 9.397 ms
Before a number of obfuscated hops and the end CDN.
17 * * * 18 * * * 19 * * * 20 * * * 21 * * * 22 server-13-249-40-8.iad89.r.cloudfront.net (13.249.40.8) 9.340 ms 9.164 ms 9.258 ms
I used the traceroute-mapper tool to visualize these hops, but it looks like their data doesn’t quite match the data I found with https://www.ip2location.com/demo; there is no Seattle in sight on the traceroute-mapper rendering! Who should we believe here?

Home -> ESPN
I live in Manhattan, so I am not very physically far from the ITP floor. However, my home network and the NYU network would be expected to have pretty different hoops to jump through, so to speak, to get to the end destination. That, in fact, proved true with the traceroute.
This route had 29 stops, with 12 stops returning ***. The first IP address is owned by Honest Networks, my internet provider. This is my IP address.
1 router.lan (192.168.88.1) 5.092 ms 2.481 ms 2.140 ms 2 38.105.253.97 (38.105.253.97) 4.323 ms 2.554 ms 3.187 ms
The next 3 are all private IP LANs -- I’m guessing these are also associated with my local device.
3 10.0.64.83 (10.0.64.83) 2.247 ms 2.302 ms 2.181 ms
4 10.0.64.10 (10.0.64.10) 3.127 ms 3.857 ms 3.588 ms
5 10.0.64.0 (10.0.64.0) 3.653 ms
10.0.64.2 (10.0.64.2) 2.214 ms 3.188 ms
The next IP address is associated with PSI-Net in Washington, DC, which appears to be a tier-1 optical provider. My guess is that Honest piggybacks off of this network, which seems to be larger and a legacy company now owned by Cogent.
6 38.30.24.81 (38.30.24.81) 2.673 ms 2.573 ms 2.061 ms
Then we see a whole lot of cogentco - owned domains, followed by IP addresses in hop 10 that are both associated again with PSInet.
7 te0-3-0-31.rcr24.jfk01.atlas.cogentco.com (154.24.14.253) 2.053 ms 2.771 ms
te0-3-0-31.rcr23.jfk01.atlas.cogentco.com (154.24.2.213) 2.712 ms
8 be2897.ccr42.jfk02.atlas.cogentco.com (154.54.84.213) 2.846 ms
be2896.ccr41.jfk02.atlas.cogentco.com (154.54.84.201) 2.280 ms 3.010 ms
9 be2271.rcr21.ewr01.atlas.cogentco.com (154.54.83.166) 3.106 ms
be3495.ccr31.jfk10.atlas.cogentco.com (66.28.4.182) 3.281 ms
be3496.ccr31.jfk10.atlas.cogentco.com (154.54.0.142) 3.611 ms
10 38.140.107.42 (38.140.107.42) 3.374 ms 3.468 ms
38.142.212.10 (38.142.212.10) 3.910 ms
We’re finally to the AWS IP addresses now for the remainder of the hops, both in Virginia and Seattle. Given how many hops there are and how prevalent AWS is for so many hosted sites, it’s hard to draw conclusions about what companies/services these hops might correspond to. But I suppose it’s another indication of just how dominant AWS is.
11 52.93.59.90 (52.93.59.90) 6.790 ms
52.93.59.26 (52.93.59.26) 4.047 ms
52.93.31.59 (52.93.31.59) 3.876 ms
12 52.93.4.8 (52.93.4.8) 3.708 ms
52.93.59.115 (52.93.59.115) 11.582 ms 6.948 ms
13 * * 150.222.241.31 (150.222.241.31) 3.954 ms
14 * * 52.93.128.175 (52.93.128.175) 3.131 ms
15 * * *
16 * * *
17 * * *
18 * * *
19 * * *
20 * * *
21 * * *
22 * * *
23 * * 150.222.137.1 (150.222.137.1) 3.128 ms
24 150.222.137.7 (150.222.137.7) 2.671 ms
150.222.137.1 (150.222.137.1) 3.558 ms
150.222.137.7 (150.222.137.7) 2.685 ms
25 * * *
26 * * *
27 * * *
28 * * *
29 * server-13-225-229-96.jfk51.r.cloudfront.net (13.225.229.96) 3.178 ms 3.992 ms

Conclusion
It really would be fascinating to see how the geographical paths of a website visit has changed over the last 25 years, when I began using the internet. A cursory search for tools or research that looked into this wasn’t fruitful, although I’m sure I could look harder and find something related. However, if you know of something along these lines, I’d love to see it!
My own analysis of my visits to espn.com, while not leading to any major revelations, put the idea of physical networks front and center in my mind, In combination with our virtual field trip, I feel like I have a much more tangible understanding of the physical infrastructure of the web than I did just a few weeks ago.
Tearable Dreams
Sketch: https://editor.p5js.org/nkumar23/sketches/GoX7ueD-x
Github: https://github.com/nkumar23/tearcloth2D
Original Plans
I originally entered this final hoping to create a sketch that visualized the quality of my sleep and was controlled by a muscle tension sensor I had already built. I wanted to visualize the entirety of my night’s sleep as a continuous fabric slowly undulating, with holes ripped through it when I clenched my jaw -- detected by the sensor.
I drafted up an initial roadmap that looked like this at a high level (sparing you the detailed steps I created for myself):
Create the fabric using ToxicLibs and p5
Adding forces and texture ripping to Shiffman’s example
Start with mouse/key interactions for rip and forces (like wind/gravity)
Create a clenched/not-clenched classification model
Collect and label sensor data for training
Create simple interface in p5 to record clench/not-clenched with timestamp so that I can label sensor values
Train ml5 neural net using labeled data
Link fabric ripping to sensor data
Run this in real time and capture video of animation during sleep
I headed into this project knowing that I’d most likely tackle chunks 1 and pieces of chunk 2, but likely not the entire thing. Along the way, I wound up focusing entirely on the cloth simulation and abandoned the rest of the project for the time being. I added some audio interaction to round out this project in a way that I thought was satisfying.
I’ll describe the process behind building this cloth simulation, and what the next steps could look like from here.
Inspiration
As difficult as dreams are to remember, I have short, vivid memories of an undulating surface, slowly changing colors, that at times looks like a grid from the matrix, and at other times looks filled in. As I began thinking of how I might want to visualize my sleep, I went immediately to this sort of flowing fabric-like image.
Luckily, as always seems to be the case, there is a Shiffman example for cloth simulation! I also found this example of a tearable cloth in native Javascript.
Process
I started with Shiffman’s 2D cloth with gravity example. He did the legwork of importing the Toxiclibs library and aliasing some important components, like the gravity behavior.
Rip detection
From that starting point, I first wanted to figure out how to rip the cloth. To begin, I calculated the distance between a clicked mouse and a particle and console logged the particle coordinates when the distance was less than 10 (i.e. which particle was clicked?).
https://editor.p5js.org/nkumar23/sketches/4NsLvcVlO
Rip detection, but make it visual
Next, I wanted to see if these particles were where I expected them to be, and nowhere else. To do this, I displayed the particles rather than the springs and made them change color upon click.
https://editor.p5js.org/nkumar23/sketches/cz2XdRYfH
Spring removal
Then, I wanted to remove springs upon click -- which would “tear” the cloth. To do this, I had to add a reference to the spring within the particle class so that specific springs could be identified upon click.
I spliced spring connections and decided to stop displaying the spring upon click, which led to this aesthetic:
https://editor.p5js.org/nkumar23/sketches/-dtg2SCCy
That doesn’t really look like a cloth was torn! Where’s the fraying? This behavior happened because the springs were not removed from the physics environment-- they were just no longer displayed.
Removing the springs required adding a bit more logic. Instead of adding springs in the draw loop, we now have the framework for adding/removing springs within the Spring class’ logic.
In the draw loop, we check whether a spring is essentially marked for removal upon click and remove it via the remove() function created in the Spring class. Thanks Shiffman for the help with that logic!
https://editor.p5js.org/nkumar23/sketches/uykP2GyE2
Adding wind + color
Now that the spring removal creates a more realistic cloth physics, I wanted to add another force to gravity - wind. I wanted to simulate wind blowing through the fabric, creating an undulating, gentle, constant motion. But I did not want the wind to blow at one consistent “speed” -- I wanted it to vary a bit, in a seemingly unpredictable way. Perlin noise could help with this.
I brought in a “constant force behavior” from Toxiclibs and created an addWind() function that incorporated changes to the parameters of the constant force vector based on Perlin noise.
Next, I wanted to add a similarly undulating change in color. As I looked at ways to use Perlin noise with color, I came across this tutorial from Gene Kogan that had exactly the kind of surreal effect I wanted. Here’s the implementation of everything up until now + wind and color:
https://editor.p5js.org/nkumar23/sketches/ugZc9Sry7
Adding sound
At this point I had a visualization that was pretty nice to look at and click on, but seemed like it could become even more satisfying with some feedback upon click-- maybe through sound! I added a piece of music I composed and a sound effect I made with Ableton Live -- the finishing touches. Check it out here -- the same as the sketch at the top.
https://editor.p5js.org/nkumar23/sketches/GoX7ueD-x
Next Steps
I would like to add some physical sensors to control parameters for this sketch — things like the way the wind blows, ways to stretch the fabric, rip it in the physical world, etc. I’m not wedded to using the muscle tension sensor anymore, though!
I’d also like to add more thoughtful sound interactions. Perhaps there are different interactions depending on when your rip the hole, where you rip it, how much of the fabric is left.
More broadly, this assignment made me want to explore physics libraries more. It is pretty impressive how nicely this cloth was modeled with Toxiclibs’ help; there’s a whole world of other physics library fun to be had.
Genetic Evolution Simulations and Athletic Performance
This week, we covered Genetic Evolution algorithms and surveyed a few approaches to designing simulations that implement this technique. Below, I’ll lay out a plan for a simulation in p5.js that takes inspiration from the improvement in athletic performance over the last 100+ years.
Scenario
Describe the scenario. What is the population? What is the environment? What is the "problem" or question? What is evolving? What are the goals?
When we watch athletes compete today, it is remarkable just how far they’re able to push the human body to achieve the feats they achieve during the games. Crowds at earlier athletic events were similarly mesmerized by the best athletes in the world during their eras. However, when we watch film of athletic competitions even 30-40 years ago, it often seems like we’re watching an amateur version of today’s sport. When we look at world record times for competitions like the 400m dash, we see a steady improvement over the years; most likely these are due to advances in technology, diet, strategy, training methods and other tools more readily available to modern athletes.
This steady march towards reaching an upper limit on athletic performance reminds me of a genetic evolution simulation. Thousands of athletes have tried to run around a track as fast as they could. Each generation of new athletes learns from the previous ones and finds little ways to improve. Over time, we see world records broken, little by little.
I would like to build a simulation that has objects try to “run” around a “track” as quickly as they can, under a number of constraints that loosely model those of real athletes. The viewer will be able to manually run each generation rather than having the simulation evolve as fast as possible, and we’ll record “world record” for the best individual “athlete” in that generation’s competition. We can display a record book on screen to see how the world records vary and eventually improve over time. We can also display the “stats” for the top n athletes to see how things like “strategy,” “technology,” and “muscle mass” change over time as the athletes improve.
Phenotype and Genotype
What is the "thing" that is evolving? Describe it's phenotype (the "expression" of its virtual DNA) and describe how you encode its genotype (the data itself) into an array or some other data structure.
Athletes, represented by shapes on the screen, are the “things” that are evolving. The athletes will be physics objects that have a position, velocity and acceleration. They’ll also have other traits like “strategy” and “technology” that loosely model real world factors that can limit or increase their max speed and vary from generation to generation. Instead of thinking of technology/strategy as properties of the object, they could be thought of as forces that are applied to the object’s acceleration or velocity vector and vary from object to object in the system.
Strategy will control the efficiency of the path taken on the track. Each frame, the object will have to decide the angle of its trajectory. If the object zig-zags around the track, it will not be taking the most efficient route. Over time, the objects should learn to take the path with the least amount of wasted movements to get to the finish line. The code will need to be written in a way that the object only goes clockwise, rather than immediately going to the finish line to the objects’ left.

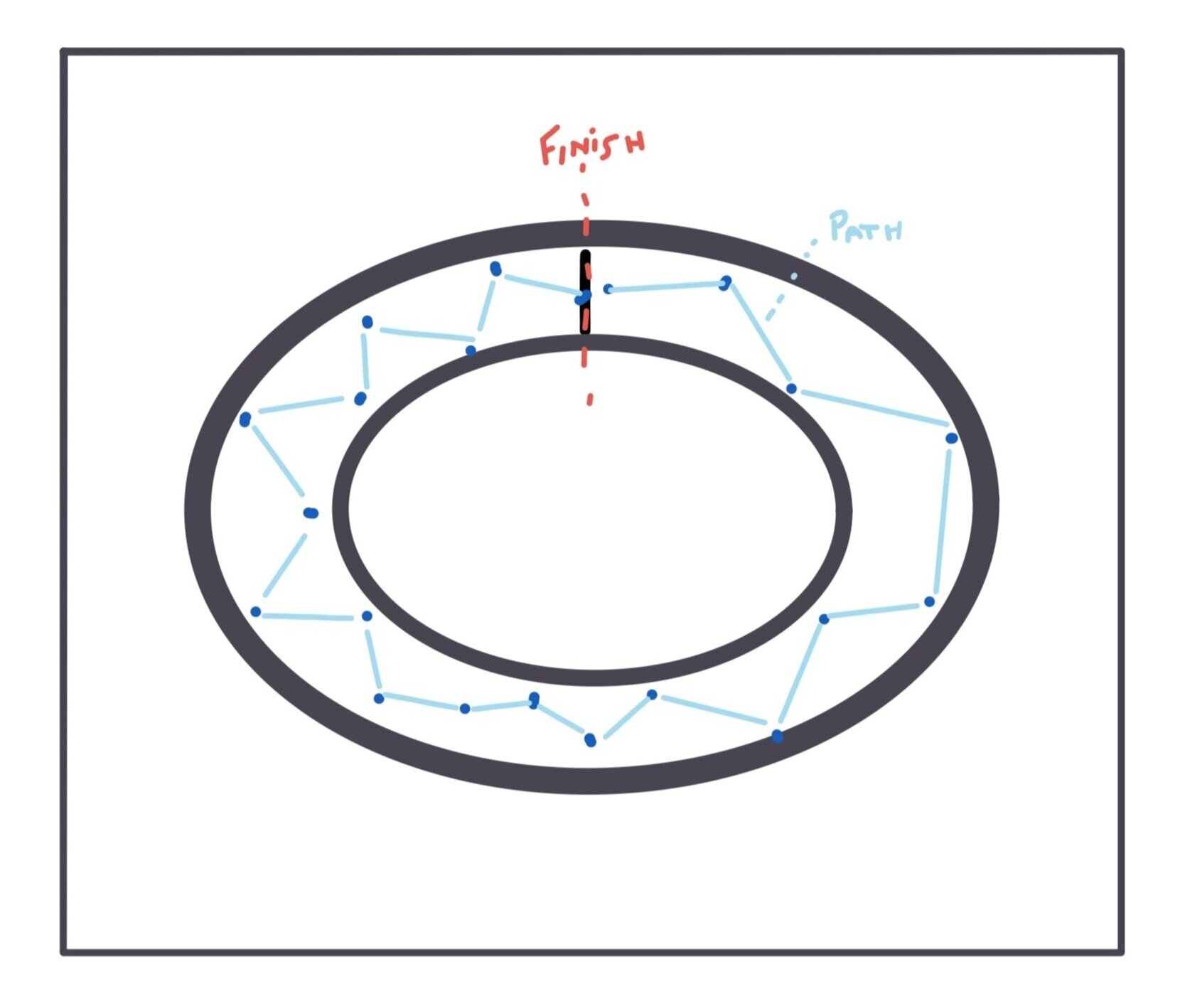

The objects will also have other constraints besides knowing the best route to run. They’ll a “technology” constraint — this will correspond to a max speed or max force property’s ceiling that applies to all athlete objects. Each athlete object’s specific technologies will allow it to reach a percentage of the ceiling — with some having “better” technology, or a higher chance of reaching the ceiling, and some will only reach, say, 50% of the ceiling, which means they will likely complete the race slower than athlete objects with better technology.
Athlete objects will also have different diets that behave similarly to technology. Diet could potentially control a “max force” constraint that affects acceleration, or could be a small velocity multiplication factor that works in conjunction with technology. This factor would apply to all objects, and each individual athlete object’s diet could vary to allow it to have a percentage of the max factor.
These properties encode the genotype and allow the athlete the potential to perform as well as their ceilings will allow them to perform. Over time, those ceilings will go up, which will allow individual athletes to go faster than the fastest in the previous generations.
The athletes’ phenotype, or expressed traits, will be their shapes and speeds of movement around the track. Perhaps diet can modulate size of the circle a bit and tech can change color or control some sort of blur effect.
Fitness Function
What is the fitness function? How do you score each element of the population?
Each generation, 20 athletes will compete. The fitness function will look for the elapsed time for the athlete to reach the finish line. Assume an oval track where the athletes begin at the top of the canvas and run clockwise as shown above. The pseudo-code to calculate the fitness function will be something like:
If athlete.pos.x equals finish.pos.x and athlete.pos.y is between a range of finish.pos.y, trigger a function that will log the time elapsed since the start of the race and the point at which the if conditions are met..
Mutation and Crossover
Are there any special considerations to mutation and crossover to consider or would the standard approaches work?
Technology and diet ceilings should probably increase on some set interval -- maybe determined by user but set at a default of every 10 generations (like a decade). Crossover can continue in a standard way and so can mutation.
Sound in... My Apartment: Plans for a Quad experiment
The last couple of weeks have been truly bizarre. I was in college in 2008 during the Financial Crisis and thought it was one of the weirder and more momentous experiences I’d lived through. This moment has quickly leapfrogged 2008, and given how terrible this situation is for so many people, I’m very lucky to be in school yet again to participate in/observe how this all unfolds.
Still, it’s been difficult to focus on schoolwork during this first wave of changes to our lives, our world. Prior to going remote, I was very excited to experiment with a quad setup at school; moving from stereo to multichannel was what I signed up for! Going remote, worrying about family and friends, making major adjustments to lifestyle, and just reading the constantly shifting news has drained my motivation tank. So, this week’s assignment is basically a sketch, a set of plans for an experiment, but not what I would have liked to do in a more-normal world.
Idea:
I would like to make a p5 + tone.js sketch that functions like a spatialization test with a twist. I’ve never worked with quad, so this would be a helpful way to start to understand some of the “physics” of different audio setups. In short, the tool will play individual notes in the form of moving balls that, when played together, can form chords. The notes will play through different channels as they collide with the “speakers” on screen.
Here is a rough skeleton of the beginnings:
As I build this out, users will be able to:
Arrange a multi-channel speaker setup on the canvas
The speakers will be rectangles with inputs to indicate the channel number
Click to create notes visualized as balls that bounce around the screen
The balls carry a note that belongs to a particular key
The note is randomly chosen from the array of notes when created
Default will be to only choose 1,3,5,8 notes from the key to create a major chord
As the balls collide with the rectangles, the note associated with the ball plays through the channel associated with the speaker.
Create many balls, increasing the chance of a chord playing through different speakers
Use the the right or left arrow to change the key that the notes are drawn from.
Use the up or down arrows to make balls move faster or slower
Hit space to clear balls
Execution Plan
I started to wire up the sketch by creating objects for the balls and rectangles. I modified an earlier particle system sketch I made, and kept the system object, which may allow for some more features down the line. I haven’t connected tone yet, which is obviously the meat of this sketch. I plan on working on this over the next 2 weeks to make it work for the binaural assignment. The first set of things I need to to do:
Finish collision detection between ball and rectangle
Add tone.js to the html doc
Hard- assign channels to each speaker
Once this work, allow input to assign channel
When collision is detected, play a sound
Make sound draw from an array of possible sounds in a key
Create arrays for different keys
Allow key to be changed
Connect slider to ball speed
Re-configure keys/mouse presses to match a good UX
Create volume slider and hook up to tone
Device to Database: Grafana and Node-Red
Assignment: Use Grafana to create a dashboard using data from the sensors we set up to measure the environment in the halls of ITP. Set up a Node-Red workflow based on that same data.
Background:
In earlier assignments, we did a few things that set us up for this week:
We built an Arduino-based temperature, humidity, and soil moisture (among other things) sensor to monitor a plant in the main hallway of ITP
We sent the data from that sensor device to an MQTT server, and then wrote a script to write that data to a variety of databases — InfluxDB, TimescaleDB, and SQLite3
We wrote queries in varies SQL-based querying languages to poke around at our data and get familiar with SQL
Now that we’ve done each of these steps, we’re able to use Grafana and Node Red with a better understanding of the more granular tasks they are abstracting away to the UI.
Results:
Grafana
In earlier assignments, I was interested in understanding the range of temperatures we would see at ITP, so I wrote queries to look at median temperature, standard deviation, and max/min values. The results came back in the terminal as values on my screen — interesting, but not visually easy to parse.
I wanted to implement the same sort of queries in Grafana to visually understand the variance in temperature as well as soil moisture for my sensor device.

You can see from the dashboard above that the temperature values stayed within a relatively narrow band. The biggest spread in temperatures was 6 degrees over the course of the periods measured. Soil moisture had a bit more variance, although the units of measurement are harder to place into context.
Curiously, the readings cut out multiple times. Most likely, given that the device was placed in high-traffic areas in the hallway, someone unplugged the device and re-plugged it later. When i picked up my device yesterday, I noticed that the usb cable had become frayed and the wires were exposed— so it is possible that the connection dropped when the cable was at the wrong position after becoming frayed.
Node Red
I want to create a workflow that calculates the average temperature based on MQTT messages, then send an alert if any value exceeds the average by 20%. I set up the flow as follows:

And I wrote the following code to calculate the average temperature and compare it to the most recent temperature value:
// put your phone number here
const phone = '12813006944'
const temperature = Number(msg.payload);
let total;
let tempHistory = [];
for (let i=0;i<tempHistory.length;i++) {
tempHistory[i] = temperature
}
function avg (array){
for (let i=0;i<array.length;i++){
total += array[i];
}
let average = total/array.length;
return average;
}
a = avg(tempHistory);
console.log(a);
msg.average = a
if ((Math.abs(a-temperature)/temperature) > .2) {
// get the device id and create a message
const device = msg.topic.split('/')[1];
const alertMessage = `Temperature ${temperature}°F for device '${device}' exceeds the high temperature limit of 80°F`
// publish to the sms topic to send a message
msg.topic = `sms/send/${phone}`;
msg.payload = alertMessage;
return msg;
} else {
return null;
}Unfortunately, before I could test this out in production, I took my device down. I could try to inject values into the MQTT to create an average, and then inject values into the message payload to check whether the alert is created — that will be my next step. Conceptually, this should work, but I still need to debug it.
SuzukiMethod
Assignment: Create a piece of music that uses stereo output
Idea and Process
I decided to start using Ableton Live for this assignment after years of working in Logic Pro. Although switching DAWs is not like starting from scratch with a new instrument, it still takes time to get up to speed with the logic (no pun intended) of the new software. Not only do you need to re-discover where the features you’re used to are located, but build an intuition for what the new software’s opinion of music-making and workflow is. Especially for these first few days of working in Ableton, I feel like — and will continue to feel like— a beginner again.
I started playing violin when I was 3. I took lessons with teachers who followed the Suzuki method; an opinionated approach to teaching music that emphasized learning through playing by ear. Reading music could come later — training the ear to hear music and repeat was more important, just like the early days of learning a spoken language. I would go to group lessons, stand with a bunch of other kids with my violin and repeat notes over and over, focusing on bow technique, then pitch, then phrases, until eventually I could play songs.
Around the same time as I was learning to play violin in the early 90s, my older brother (also a violinist) was listening to a lot of New York rap when we weren’t practicing classical music. The Wu-Tang Clan was at their peak, and their prodigal producer, the GZA, released Liquid Swords. I knew a lot of the lyrics, even if I didn’t know the meaning, of the eponymous title track off of the album; it’s remained one of my favorite + most-quoted songs of all time.
For this assignment, I wanted to start the process of switching to Ableton, knowing full well that it might not be pretty initially. I will likely use Ableton as we move to exploring 4+ channel output, so I wanted to start to develop a workflow to work in stereo-and-beyond.
I chose to sample audio from a Suzuki lesson during which Suzuki instructs kids on the bow motion needed to play Jingle Bells. I also took the drums from the end Liquid Swords; in typical early-90s fashion, it’s repetitive and only really has a kick and snare. Working with these samples is a reminder that it’s going to take some time to have my output sound the way I want it to; I need to practice + have patience.
I focused on learning how sampling works in Ableton. I chopped the audio from Suzuki and Liquid Swords and mapped it to my MIDI controller; it’s easier to do and more fully-featured than in Logic. I played with random panning and spread on the Suzuki vocal samples, two features that are immediately accessible in the sampler, but would have taken work to access in Logic. I was also easily able to take the violin samples and map them to a scale using the transpose pitch feature.

I also started to work with the EQ effects. I know I have a lot of work to do to make the mix sound good, but I started by trying to place the drums, violin samples, and vocals in different parts of the stereo mix. I then used the EQ effect to cut or boost different parts of the frequency spectrum for each of the sounds. I also created a mid-pass filter at the beginning to create some contrast on the drums/violins/vocals before the beat really comes in. The EQing could use a lot of work — I’d love to get some tips in class for how to approach EQing.
Ultimately, I wanted to create a groove that you could bop your head to and maybe even have a friend freestyle on, while trying to get sounds to have a clear sense of place within the space inside the mix. The violins were meant to gradually get more spacious and disoriented as I applied more echo/reverb. I’m not sure it fully succeeded in any of these goals: the piece has a bit of motion as different drums come in, but could stand to have a bit more variation, and could definitely have a cleaner placement of sounds. The violin volume levels aren’t quite right yet. I’m still happy with getting off the ground and making something I can build off of. Looking forward to spending some nights getting lost in learning Ableton and getting better at production!
Particle Systems -- work in progress
Assignment: Build a particle system
Idea
This week, I wanted to make a system of blobs that looked like bacteria moving around the screen. I envisioned a mix of different bacteria with a bunch of common characteristics, but different colors and perhaps shapes or other features. I wanted to use the “extend” functionality of JavaScript to work with inheritance and give these different bacteria unique differences.
To do this, I started by modifying Shiffman’s Coding Challenge to create a blob with bacteria-like qualities, using things like p5 Vectors to get it ready for object-izing. Code here
I knew I would need to create a blob class that I called “Blobject,” which would have its aesthetic characteristics in a “display ()” function and other characteristics, like its ability to update/move, in other functions.
I also knew that I would need to pay special attention to where the blobject started on the screen, likely through its Vertex coordinates.
Finally, I would need to extend the Blobject to create another object (I called it a “Bluebject”) that could get added to the sketch from a “Blobject System” object.
Along the way, however, I got tripped up trying to make all of these things happen. I started with existing code examples and began modifying — but I may have been better off trying to write functions from the ground up, as I think I spent more time trying to backwards engineer code that wasn’t perfectly suited for my use case.
I feel like I’m close, but I have to cut myself off right now for the sake of not staying up all night. In my eventual- particle system sketch, I have this:
I need a bit more time to finish debugging, but I’m going to make it happen!
Listening to Bio-Signal (Or: JAWZZZ)
Assignment: Expose a signal from some under-represented part of your body.
Idea
Our bodies produce signals that we can’t see, but often can feel in one dimension or another. Whether pain or restlessness, euphoria or hunger, our body has mechanisms for expressing the invisible.
Some of its signals, however, take time to manifest. Small amounts of muscle tension only convert into pain after crossing some threshold — which, in some cases, could take years to reach. I clench my teeth at night, which only became visible a few years ago when the enamel on my teeth showed significant wear and tear. At various times, I had unexplainable headaches or jaw lock; but for the most part, my overnight habits were invisible and not sense-able.
With technological prostheses, however, we can try to shift the speed at which we receive signal. This week, I built a muscle tension sensor to wear on my jaw while sleeping with the hope that I could sense whether I still clench my jaw. Long story short: I most likely do still clench my jaw, but without spending more time on statistical analysis of my results, it’s not wise to read too deeply into the results.
I’ll go over the process and results, but perhaps the most important reflection in this whole process is that even in my 3-day experiment, it was possible to see the possible pitfalls that accompany trying to quantify and infer meaning from data in situations that include even minimal amounts of complexity.
Process
This experiment required the following pieces:
Wire together a muscle tension sensor and microcontroller
I used a MyoWare muscle sensor and Arduino MKR WiFi 1010
Send data from the sensor to a computer
I used the MQTT protocol to wirelessly send data from my Arduino to a Mosquitto server
Write the data from the server to a database
I used a node.js script to listen to the MQTT data and write it to a local SQLite database on my computer
Analyze data from the database
I used Pandas, Matplotlib — common Python libraries— and the SQLIte package to shape and analyze my data
[As a side note: prior to this assignment, I had not used a number of these different technologies, especially not in such an interconnected way. The technical challenge, and the opportunity to learn a number of useful skills while tackling these challenges, was a highlight of the week!]
I started by assembling the hardware and testing on my forearm to make sure it worked properly:

I then moved to testing that it could sense jaw clenching (it did):

Ultimately, I put it to the test at night. The first night I tried to use the sensor, my beard seemed to interfere with the electrodes too much. In true dedication to science, I shaved off my beard for the first time in years :P It seemed to do the trick:

Results
OK, so— what happened?
First, the basics: This data was collected on Saturday night into Sunday morning for ~8 hours. I wore the sensor on my right jaw muscle and took 2 readings per second the entire time.
And a few caveats: this is only one night’s worth of data, so it is really not conclusive whatsoever. It’s really just a first set of thoughts, which can hopefully be refined with more data and Python know-how. I also did not capture film of my sleeping to crosscheck what seems to be happening in the data with what actually happened in real life.
With that said, here’s one explanation of what happened.
Throughout the night, it’s likely that I shifted positions 5-10 times in a way that affected the sensor. In the graph below, there are clusters of datapoints that appear like blue blocks. Those clusters are periods where the readings were fairly consistent, suggesting that I may have been sleeping in one consistent position. These clusters are usually followed by a surge in reading values, which happen when the sensor detects muscle tension, but also happened when I would touch the sensors with my hand to test calibration. When sleeping, it’s possible that I rolled over onto the sensor, triggering periods where the readings were consistently high.

During those fairly-stable periods, there are still a lot of outlying points. By zooming into one “stable” area, we can look at what’s happening with a bit more resolution:

This is a snapshot of 1 minute. During the beginning of the snapshot, the sensor values are clustered right around a reading of 100. Then there is a gap in readings— the readings were higher than 400 and I didn’t adjust the y-axis scale for this screenshot— then they return to ~100 before spiking to 400. The finally begin returning to an equilibrium towards the end of the minute.

This could be evidence of the jaw-clenching that I was looking for initially. It would be reasonable to expect jaw clenching to last only for a few seconds at a time, but that it could happen many times in a row. Perhaps this data shows this in action — I am sleeping normally, clench my jaw for a few seconds, relax again for 5 seconds, and then clench my jaw for another 5 seconds before letting up.
Ultimately, it looks like this sensor data may unveil 2 behaviors for the price of 1: shifts in sleeping position + jaw clenching!
Reflections
In order to make these insights somewhat reliable, I need to do a few things:
Collect more data
This is only one night’s worth of data. It’s possible that this is all noise, the sensor didn’t actually work at all, and I’m just projecting meaning onto meaningless data. A bigger sample size could help us see what patterns persist day after day.
Collect data from different people
In order to validate the hypothesis that high-level clusters explain shifts in position and more granular clusters/outliers show jaw clenching, I’d need to try this with other people. I know that I clench my jaw, but if someone who doesn’t clench still has similar patterns in data, I’d need to revisit these hypothesis.
Validate insights against reality
If I had video of my night, or if some house elf took notes while I slept, we could tag different actual behaviors and timestamps. Capturing shift in position should be relatively easy to do, as long as I get the lighting figured out. Clenching might be harder to capture on video.
Statistical analysis
I used the scatterplot to see obvious visual patterns. Using some clustering analysis, I could understand the relationships between clusters and outliers at a more detailed level.
Beyond what I could do to improve this analysis, I think there’s a bigger point to make: we should be skeptical of the quantified data we are presented with and ask hard questions about the ways in which the presenters of data arrived at their conclusions. In my experiment above, I could have made some bold claim about my sensor being able to detect sleep positions and TMJ-inducing behavior, but the reality is that the data needs a lot of validation before any insights can be made confidently. While academia has checks and balances (which themselves have a lot of issues), the rise of popular data science and statistics has not been coupled with robust fact-checking. So — before going along with quantified-self data, make sure to ask a lot of questions about what might be causing the results!
Thanks to Don Coleman and his course Device to Database — extremely helpful for this technical implementation of this project.
Plant Monitoring Sensors
Assignment: Use temperature, humidity, soil moisture, and UV sensors to monitor a plant’s environment + send that information to an MQTT server.
Process and Results:
Setting up the sensors was fairly straightforward; I followed these templates for soil moisture and temperature/humidity, then added readings for UV, illuminance, and pressure following the same steps we took to get the other readings into the right format. To make changes to the code I needed to 1) create a new MQTT topic for each reading, 2) define the sensor reading variable, 3) actually send the MQTT message and 4) print out the new readings to the serial monitor.
Initially, I kept the sensor readings at 1 per every 10 second interval, but today I switched it to every 2 minutes. This may be too short as well— the readings are unlikely to change a whole lot in the building— but in case we want more data to analyze in class, I over-collected. I’ve been able to get consistent readings so far and am looking forward to learning how to get these readings into a database during class.
My plant is located along the hallway outside of the ITP floor, in front of the second bathroom stall, with a blue label attached to it.
You can find the source code after the pictures below.



Source Code
Find the source code here.
Video Perform System Update
My main goals this week were to get a MIDI controller to control effects, to add menus for video selection, and to add more effects to my system. I accomplished 2 out of 3, but not for lack of trying!
MIDI Control of Effects
I successfully hooked up a MIDI controller to control 4 different effect parameters, and will be able to continue adding more. I followed this tutorial to learn how to use the “ctlin” object with MIDI and re-used this code for each of the effect sliders. My guess is that there is a more efficient way to do this, perhaps by increasing the number of inputs in my gate object to the number of parameters I’d like to control. I haven’t tried this yet, and I at least know that my current method will work if all else fails. The one downside to my approach that I’ve already seen is that I have to carefully “train” each slider object to recognize the right knob on my MIDI controller each time I load Max. If not done carefully, one knob can accidentally control multiple parameters (which could be very helpful, given the right intention!)
One more thing to improve: setting the right range for mapping values from the slider to the inputs into the effects patch. For example, the knob on my MIDI controller currently sends values from 0-127. I am re-mapping those to Brightness, Contrast, and Saturation. For each of those, I will need a range that goes from a negative value to a positive value. I re-mapped 0-127 to -500,500 initially; this range is probably too big, and doesn’t allow me much granularity close to 0. I’ll play with these ranges over the course of the week.
Adding Effects
I added the jit.op object in two places; one as feedback on the final video before output to the window, and one as the sum of two incoming videos. I am not sure that I have the feedback channel wired up properly right now; it’s possible that I am feeding in two video feeds and while one of them is receiving feedback, the other is coming in clean, leading to the blinking effect in the screen recording.
UMenu Fail
I did not, however, get the UMenu to work properly. I added filepaths to my File Preferences

And I added filenames without spaces to the the UMenu inspector option:

But when trying to load these into the patch, I was never able to successfully play any videos. I reverted back to just using the “read” object.
Last Thoughts
The added effects are nice, and I will continue to experiment with them. However, the biggest takeaway is that the source video can make a big difference. I used microscope-based videos and they lent a really interesting quality when simply overlaid. I want to be very familiar with the videos I have at my disposal, even moreso than the effects that I can apply, for my performance.
Fun with Polar Roses
Overview
I set out this week to explore using springs and forces + step up my object-oriented programming game. I ended up doing neither thing. Instead, I started making roses with polar coordinates and wound up getting sucked in to a game of “what does this do?” In the process, I wound up tinkering my way to a better understanding of the relationship between polar and cartesian coordinates + got a better sense of how some interesting visuals that could be incorporated into audiovisual performance can be created.
Video Performance System in Max - Step 1
Reflections
My goal this week was to just get something basic to work. I wanted to explore objects that I hadn’t used, get familiar with some of the oddities of programming in Max, raise questions, and start to get a clearer sense of what I might be able to do — so that I can start to refine a conceptual idea for our upcoming performance.
I’d say I succeeded in hitting the goal: something works. Not everything I tried worked, which is a good thing I suppose. It definitely means I have questions to answer, and avenues to explore tomorrow and the following days. I didn’t venture too far from example effects, but I’m OK with that for this week. Since the goal was getting familiar with basics and getting basic mistakes out of the way, I will cut myself some slack for not figuring out any novel effects.
The main objects I used this week were jit.brcosa to control brightness/contrast/saturation and jit.slide to do an interesting pixel smoothing effect. I also used jit.xfade to create a crossfader between two videos. I added a handful of control buttons for the jit.movie objects, but overall would love to see examples of a solid layout/UI for a performance-ready patch.

Even with just 2 effects and a crossfader, we can see pretty cool visuals!
A few immediate questions:
What is the functional difference between qmetro and metro?
How do we use jit.rota?
I tried feeding it a theta value and patching the whole thing into the flow after jit.slide (and tried other connections too) but didn’t see any results.
When do we need to use loadbang
Why does the video unreliably play back? Occasionally I have to re-read the video file for it to play. Other times I can just hit play, or any bang.
What’s the best way to wire up multiple effects going to multiple videos?
Is it possible to get a multi-video fader, like a fader board?
My Microbial Companion: Nukazuke
Assignment:
Start a microbial culture that you will keep as a companion for the rest of the semester.
Idea:
Nukazuke are Japanese rice-bran ferments. They’re made by first preparing a bed of rice bran, salt, water and additional ingredients like mustard powder, kombu, dried red chili flakes and garlic. Other add-ons can be used instead of these. After mixing together the ingredients, bury a vegetable, chopped if necessary but with skin-on, in the rice bran bed. The salt in the rice bran bed functions just like salt in a lacto-ferment; it promotes healthy lactobacilus growth and inhibits other pathogenic bacteria that can’t survive in higher-salt concentrations. The rice bran supplies sugar for the naturally occurring bacteria in the air, and the buried vegetable (especially its skin) often carries a lactobacilus biome that will help begin culturing the rice bran bed.
Each day until mature, swap out the vegetable in the bed. This helps promote a more diverse microbiome in the rice bran bed. I’ve been tasting the pickles each of the last two days; they are noticeably transformed from their normal state, slightly sweeter and saltier, but still very young for a nukazuke. I expect that within a week I will have a mature bed.
Once the bed is mature, I’ll be burying vegetables or ~12 hours or more to get the fermented final product. I’ll try different vegetables, and eventually I may take some of the mature culture to
I followed this recipe, and also learned a lot from The Art of Fermentation by Sandor Katz.
The Futility of Attraction (Plenty of Fish)
Assignment:
Use concepts related to vectors and forces to create a sketch with a basic physics engine.
Idea Summary:
Sometimes the harder you try, the harder it is to find love! In this Valentine’s Day sketch, you are the circle at the center of the sketch and are trying to “find love” by intersecting with another circle and staying with it over time. However, the longer you try to stay with the companion circle, the more it will try to get away! Sad. There are, however, always more fish…erh, ellipses… in the sea… sketch… whatever.
Background and Process:
I used Shiffman’s sketch about “attraction with many movers” as the model for my sketch. My goal for the week was to successfully deconstruct this sketch and get a good understanding of how velocity, acceleration and forces work with vectors. I also wanted to shake off the rust and make sure I could implement collision detection and edge checking.
I’ll skip over the tales of failed relationships that left me momentarily jaded while creating the sketch :P Don’t worry— my optimism tank refills quickly!
While de/re-constructing the sketch, there were a few simple takeaways.
To implement edge checking, I needed to change both the x and y position and also the x and y velocities; this is the equivalent of changing x,y, and speed when recalling our nomenclature in ICM.
To flip attraction to repulsion, I needed to flip the sign of the force’s strength
To do collision detection, I wanted to check to see moments when the combined radii of the attractor and mover were equal. I realized after some unsuccessful attempts that I needed to shift to checking an inequality since floats are rarely exactly equal.
To make the acceleration of repulsion faster, I made the range of the constrain function narrower.
Sound in Space Mono: Prepared Violin
Assignment:
Create sounds that play from a single (mono) output
Idea summary:
I created a “prepared violin” by attaching various resonant objects to the strings of my violin. The resulting sounds added new dimensions to the texture and harmonic quality of the traditional classical violin output. The violin itself is the mono output source.
Background:
This semester, we will be gradually building towards performing on a 40 channel setup. As we progress through increasingly more complex output arrangements, I will undoubtedly build up my understanding of technical tools like Max/MSP and get deeper into the weeds of DAWs like Ableton/Logic. For this first assignment, instead of jumping into those tools or arranging a piece of music, I wanted to start analog.
A mono output source can be anything from a single speaker to a single human voice. As a violinist for most of my waking life, albeit an infrequent one these days, I decided to use this assignment to dust off the strings and treat my violin as my mono output. Before diving into the details — one question to ponder: is the violin itself the mono output or is each string the mono output? The strings need some chamber in order to have their vibrations amplified enough to hear, so in this sense, I suppose the whole violin with its hollowed out body is the output source… But I’d love to hear the argument in favor of each-string-as-mono too!
Anyways. I wanted to try to experiment with the sounds my violin could produce. I used John Cage’s experiments with prepared pianos as inspiration. In his pieces, Cage placed different in/on the strings of his piano, completely altering their sonic properties. Sometimes strings were muted, instead lending a kind of percussive quality. Other times, the piano sounded like a distorted electronic instrument whose formats had been shifted. Could I get something similar from my violin?
Process:
Pianos are big, with enough space (and flatness) to stick a ping pong ball between strings. Violins are not big and are not flat between strings. Still, some objects would definitely still alter the properties of strings. I landed on 4 different experiments:
a single safety pin,
two safety pins (one small enough to clip around string, one large enough to cross two strings),
a metal nail
and a stripped electrical wire
Each of these objects did a couple of things — they changed the way the violin string vibrated and they also vibrated themselves. As a result, in each of the following videos, the violin produced novel sounds. The safety pins bounced and shifted as they vibrated; plucking strings to optimize for bouncing the safety pins led to the most interesting sounds. All of the objects produced interesting harmonics when they lightly touched the violin strings, however my favorite example is the wire. After wrapping the wire around the G-string, there was a bit of a handle that I could use to slide the wire up and down the string. You can hear the harmonics change as I slide the wire around.
I’ve included clips from each of the experiments below
Single safety pin:
Plucking Safety Pin
Two clothespins
Nail
Plucked nail
Wire
Next Steps:
While not every sound produced here is immediately appealing, all of them do have some unusual property that I could work into compositions. I’d like to record these into a sample bank and then apply audio effects to create some wholly new textures for use in a future piece of music, perhaps in the stereo assignment. Many of the electronic artists I enjoy listening to, from Aphex Twin to Flying Lotus, record their own analog sounds before manipulating them into the samples that sound so foreign; with my prepared violin experiments, I think I’ve found the beginnings of some interesting audio samples to use later.
Another interesting challenge that would keep me in the realm of mono performance: I could try to compose a piece using just my prepared violin. In this assignment, I looked for new sounds and textures without constraining myself around fitting these sounds into a composition. Getting these sounds to work in their raw form without digital manipulation would be a fun, albeit difficult, next experiment!